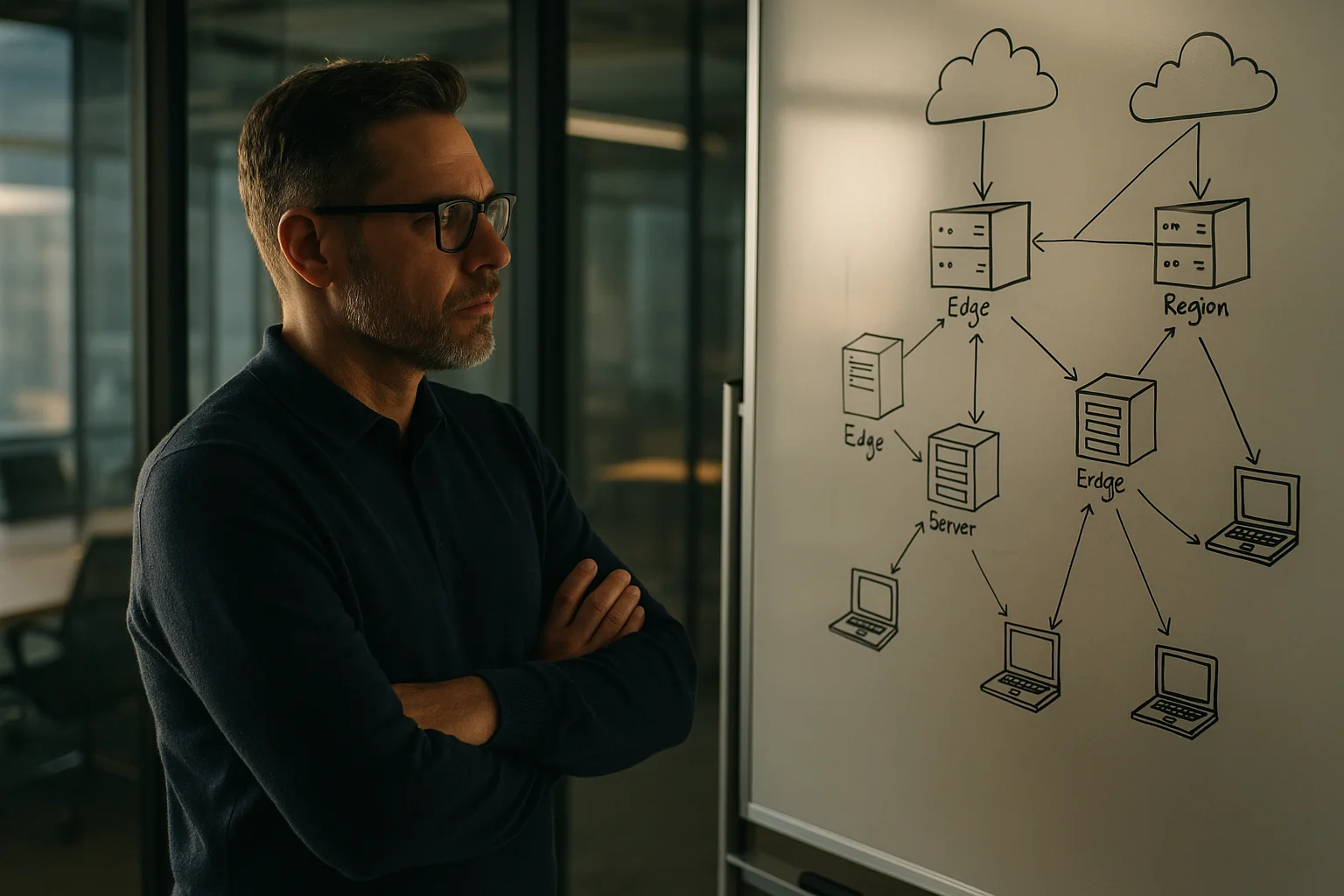
L’agent IA que vous avez montré dans un notebook n’est pas celui que vous mettrez en production. Ce qui détermine s’il sera rapide, conforme, abordable et observable, ce n’est pas le nom du modèle sur votre slide — c’est la couche d’inférence que vous choisissez et la façon dont vous concevez l’architecture autour.
Ces dernières semaines, Cloudflare a présenté une couche d’inférence « conçue pour les agents », en poussant le calcul à l’edge. OpenAI a étendu les capacités de contrôle du poste de travail, rendant très tangibles des agents capables d’utiliser votre ordinateur en arrière‑plan. Mozilla a dévoilé un client axé sur l’infrastructure auto‑hébergée. Pendant ce temps, des modèles ouverts comme Qwen3.6-35B deviennent aptes à opérer en mode agent. Traduction : le choix de plateforme est désormais le choix de produit.
Si vous êtes CTO, il faut choisir votre voie. Voici un cadre pragmatique pour le faire.
La vraie question n’est pas « quel modèle ? » mais « où et comment l’exécuter ? »
Les benchmarks et classements sont bruyants. En production, ce qui compte, c’est le budget de latence, le contrôle des données, la stabilité des coûts et l’opérabilité. Un agent qui paraît réactif à 250 ms p50 et 800 ms p95 avec une piste d’audit propre battra un agent légèrement plus “intelligent” qui met 2,5 s et dissémine des secrets dans les logs.
Définissez le niveau de capacité de votre agent (et le risque implicite)
- Niveau 0 : Chat et RAG. Questions‑réponses sans état. Usage minimal d’outils. Faible rayon d’impact.
- Niveau 1 : Appels de fonctions et orchestration d’API. Écritures dans des systèmes internes derrière un IAM strict.
- Niveau 2 : Navigation, I/O fichiers et exécution de code en sandbox. Rayon d’impact moyen.
- Niveau 3 : Contrôle du poste de travail ou d’une console cloud (p. ex., shell, automatisation GUI). Fort rayon d’impact, nécessite isolation et enregistrement.
- Niveau 4 : Boucles autonomes avec tâches en arrière‑plan et planification. Rayon d’impact maximal. À traiter comme un compte de service privilégié avec freins.
Le choix de votre couche d’inférence doit suivre le niveau le plus élevé que vous comptez supporter dans les deux prochains trimestres — pas la démo de la semaine dernière.
Un cadre de décision en sept questions
1) Quel est votre budget de latence et où sont vos utilisateurs ?
- L’inférence à l’edge (p. ex., sur un réseau global) peut gagner 50 à 150 ms en éliminant les liaisons longue distance et les cold starts pour les expériences chat+RAG.
- L’inférence régionale (AWS, GCP, Azure) ajoute 30 à 120 ms par appel selon le peering et la configuration VPC. Souvent préférable pour les workflows back‑office.
- L’on‑device peut atteindre 30 à 80 ms pour de petits modèles mais sacrifie capacité et constance ; idéal pour des tâches très sensibles à la confidentialité ou occasionnelles.
Règle pratique : si votre fonctionnalité doit paraître instantanée (p95 sous 1 s) et que vos utilisateurs sont répartis globalement, privilégiez l’edge ou une architecture scindée avec un routeur edge, des embeddings/rerankers locaux et un « cerveau » régional.
2) Quelles données manipulez‑vous et où doivent‑elles résider ?
- PHI, PCI ou politiques PII strictes vous orientent vers de l’inférence hébergée en VPC ou des fournisseurs avec résidence des données exécutoire et absence d’entraînement sur les entrées.
- La minimisation des données et la tokenisation au niveau de la passerelle réduisent le risque et le verrouillage fournisseur. Faites le masquage avant l’inférence, pas après.
- Pour la résidence en UE/Amérique latine, prévoyez des déploiements doubles. Les sauts transfrontaliers ruineront à la fois la latence et votre récit de conformité.
3) Quels outils l’agent utilisera‑t‑il et comment les isoler ?
- L’appel de fonctions vers des services internes exige des requêtes signées, des allowlists par outil et des plafonds de budget par tour.
- Le contrôle d’un poste ou d’une console requiert des VM/microVM éphémères, l’enregistrement des sessions et des identifiants par tâche avec un RBAC strictement borné.
- La navigation web nécessite des moteurs de rendu sûrs et une désinfection du contenu ; n’autorisez jamais un agent à exécuter du JavaScript arbitraire dans votre réseau de prod.
4) Quel SLA et quel risque fournisseur pouvez‑vous tolérer ?
- Les endpoints publics de fournisseurs fermés offrent des modèles de pointe mais peuvent brider ou changer les conditions. Prévoyez un modèle de secours et une couche de routage.
- Les réseaux edge peuvent être résilients mais ajoutent une dépendance à la disponibilité des POP et aux fonctionnalités du vendeur. Validez l’arriéré de modèles supportés et la cadence des mises à jour.
- L’auto‑hébergement donne le contrôle mais transfère l’astreinte disponibilité à votre équipe. Budgétez des heures SRE. Pas de miracle.
5) Vos unit economics peuvent‑ils converger ?
Remontez à partir d’une tâche : en moyenne 300 tokens d’entrée, 800 tokens de sortie, 2 appels de fonction. Multipliez par votre volume mensuel de tâches. Puis construisez deux scénarios :
- Modèle fermé premium pour la cognition + reranker/embedding open bon marché à l’edge.
- Pile tout‑open affinée/LoRA pour votre domaine.
Nous observons couramment des variations de coût de 20 à 40 % selon ce que vous délestez vers les rerankers et selon l’agressivité du batching ou du cache des embeddings. Tenez aussi compte de l’egress du vector DB ; garder rerank et recherche vectorielle co‑localisés avec l’inférence évite des factures réseau absurdes.
6) Comment allez‑vous observer, évaluer et revenir en arrière ?
- Chaque étape de l’agent doit émettre des spans avec outil, tokens, latence et coût. Échantillonnez prompts/completions bruts avec masquage.
- Exécutez chaque nuit des évaluations synthétiques sur un corpus fixe. Suivez le taux de réussite et les variations d’hallucination par version de modèle.
- Faites des modèles un simple toggle de config. Publiez avec un kill switch et entraînez‑vous aux rollbacks comme vous vous entraînez à la réponse à incident.
7) Quelle est votre trappe de secours ?
- Gardez prompts, schémas d’outils et garde‑fous agnostiques vis‑à‑vis des fournisseurs. Utilisez une couche d’adaptation pour que les changements de modèle n’affectent pas le code produit.
- Maintenez au moins une voie modèle open‑source (vLLM/ollama) pour assurer la continuité lors d’indisponibilités ou de changements de prix.
Vos options de plateforme, sans le battage
Cloudflare Workers AI (edge) + Vectorize + KV/Queues
Cloudflare positionne explicitement sa plateforme AI comme une couche d’inférence pour agents, avec des POP globaux et une intégration étroite entre stockage et réseau. Avantages concrets : peu de cold starts, faibles latences de queue et mouvements de données intra‑plateforme peu coûteux.
- Forces : plus de 300 POP, latence au plus près de l’utilisateur ; composition facile avec KV/Queues/Durable Objects ; bon pour chat+RAG et un usage léger des outils.
- Contraintes : profondeur du catalogue de modèles variable ; jobs longs ou très GPU‑intensifs parfois mal adaptés ; options de fine‑tuning limitées face aux hyperscalers. Vous acceptez la feuille de route du fournisseur comme facteur bloquant.
- Bon choix : fonctionnalités produit où le p95 sous 1 s est crucial et où la sensibilité des données est maîtrisable via masquage/tokenisation.
Référence : voir la vue d’ensemble de la plateforme AI de Cloudflare pour le support modèle actuel et les patterns architecturaux (blog.cloudflare.com/ai).
AWS Bedrock + Lambda/ECS + VPC (regional)
Bedrock vous offre un menu de modèles fermés et ouverts de haute qualité dans votre périmètre VPC, avec IAM et PrivateLink. C’est ennuyeux dans le bon sens.
- Forces : IAM entreprise, CloudWatch, KMS ; histoire de conformité ; co‑localisation avec vos sources de données ; évolution régulière (agents, guardrails).
- Contraintes : latence régionale ; opacité des coûts quand on mélange des services managés ; contraintes occasionnelles de capacité des modèles ; vous devez toujours concevoir votre propre routage et vos évaluations.
- Bon choix : agents back‑office, workloads PII/PHI, automatisations internes où l’audit l’emporte sur la latence absolue.
OpenAI/Anthropic endpoints (managed cognition)
Modèles de raisonnement de très haut niveau, fort function‑calling, planification d’usage d’outils, et désormais des capacités système plus affirmées comme le contrôle du poste en arrière‑plan.
- Forces : raisonnement et code best‑in‑class ; améliorations fréquentes ; prototypage facile ; bonnes sémantiques d’usage d’outils.
- Contraintes : conditions et limites de taux du fournisseur ; contrôle des données dépendant des réglages et accords entreprise ; saut sur internet public et egress ; le sandboxing est à votre charge.
- Bon choix : quand la qualité de raisonnement domine et que vous pouvez atténuer le risque de données via masquage, ou pour des appels « cerveau » derrière un edge/routeur et un pré/post‑traitement par modèles ouverts.
Référence : les blogs des fournisseurs annoncent des évolutions rapides ; prévoyez un contrôle des changements (openai.com/blog, anthropic.com/news).
Self-hosted open models with vLLM/Ollama on Kubernetes (VPC)
Si le contrôle des données et la prévisibilité des coûts priment sur le QI brut, auto‑hébergez. vLLM offre un serving à haut débit ; les modèles ouverts modernes (Qwen, Llama, Mistral) deviennent très capables, surtout avec tuning domaine et reranking.
- Forces : contrôle total des données ; coût prévisible à l’heure GPU ; possibilité d’exécuter des modèles quantifiés sur de plus petits GPU/CPU pour des chemins non critiques ; évite le lock‑in.
- Contraintes : vous faites le SRE ; cycle de vie des modèles et discipline d’évaluation à votre charge ; maintenir l’état de l’art exige un tuning continu.
- Bon choix : données régulées, scénarios hors‑ligne/air‑gap, ou RAG à haut volume sensible au coût où la qualité au 95e percentile n’est pas obligatoire.
On-device (mobile/desktop)
Avec de petits modèles quantifiés et des NPU mobiles de plus en plus capables, l’inférence on‑device est réelle pour des tâches étroites (résumé, classification, masquage côté client, vérifications d’âge).
- Forces : confidentialité, hors‑ligne, latence réseau minimale, gains potentiels de conformité quand l’inférence ne quitte jamais l’appareil.
- Contraintes : taille et contexte de modèle limités ; complexité de distribution et de mise à jour ; accélération matérielle fragmentée.
- Bon choix : fonctionnalités privacy‑first, pré/post‑traitement, tâches de gating avant la cognition côté serveur.
Architectures de référence qui tournent en production
1) Fonctionnalité grand public : chat + RAG à faible latence
- Routeur edge sur Cloudflare (ou équivalent) pour la terminaison des requêtes, le masquage, le rate limiting et les feature flags.
- Embeddings et rerankers en edge pour la sélection de candidats depuis un magasin vectoriel co‑localisé. Cache agressif.
- Appels « cerveau » vers un modèle premium régional (OpenAI/Anthropic ou Bedrock) uniquement quand nécessaire. Contextes courts, outils sous garde‑fous.
- Observabilité : logs au niveau des spans avec compte de tokens, p50/p95 par étape, et échantillons de transcriptions avec PII masquées.
Nous avons vu réduire la latence médiane de 25 à 35 % par rapport aux conceptions « region‑only », avec 15 à 25 % de réduction de dépense LLM grâce à un pré‑filtrage plus intelligent.
2) Agent interne back‑office avec données sensibles
- Exécutez l’inférence dans votre VPC (Bedrock ou vLLM) derrière une passerelle OIDC. Tous les outils exigent des JWT signés et des rôles IAM par périmètre.
- Centralisez les secrets dans votre coffre standard ; jamais dans les prompts. Journalisez tous les appels d’outils dans un stockage append‑only.
- Utilisez un moteur de politiques pour approuver/refuser les actions au‑delà d’un seuil de risque (p. ex., paiement > 1000 $ nécessite confirmation humaine).
- Évaluations nocturnes sur un jeu doré ; des garde‑fous de régression bloquent les nouvelles versions de modèle qui se dégradent au‑delà des marges convenues.
Attendez‑vous à des latences légèrement supérieures (p95 900–1400 ms), mais à une auditabilité et une gouvernance des données qui passent l’examen externe.
3) Automatisation desktop/console (fort rayon d’impact)
- Ne laissez jamais l’agent toucher un vrai poste utilisateur. Lancez des microVM ou conteneurs éphémères avec une identité jetable et des identifiants par exécution.
- Utilisez un cerveau à deux niveaux : modèle fermé pour la planification ; modèle open auto‑hébergé pour les étapes itératives à faible risque afin de maîtriser le coût et éviter les rate limits.
- Enregistrez la session (vidéo + logs), limitez temps d’exécution et budgets de tokens, et exigez une approbation humaine pour les actions destructrices.
- Faites passer tous les téléchargements par un moteur de rendu sûr et un scan AV. Les sorties réseau sont verrouillées sur des allowlists.
Oui, c’est plus lourd. Mais c’est la différence entre une démo contrôlée et un système de production que vous pouvez défendre lors d’une revue d’incident.
Contrôles de sécurité qui comptent plus que votre choix de modèle
- Masquage à l’edge : suppression des hash/emails/SSN avant les prompts. Conservez les originaux dans un magasin scellé indexé par jeton si vous devez réhydrater après l’inférence.
- Allowlists d’outils + budgets : N appels d’outil max par tour, dépense max par session, et périmètres par outil. Refusez par défaut.
- Timeboxing : timeouts durs et watchdogs sur les boucles d’agent. Pas de jobs éternels en arrière‑plan sans ordonnanceurs que vous contrôlez.
- Traçabilité des données : taguez chaque artefact avec la version de modèle, le hash du prompt et la chaîne d’outils. Rendez possible la réponse à « qu’est‑ce qui a produit ceci ? »
- Tests de jailbreak en CI : prompts de red‑team commités dans votre dépôt. Exécutez‑les à chaque montée de version de modèle avant déploiement.
Mesurer le succès : des KPI qui vous gardent honnêtes
- Latence : p50/p95 par étape (embed, rerank, LLM, outils), pas seulement de bout en bout.
- Qualité : taux de réussite des tâches depuis les évaluations nocturnes ; taux de factualité/hallucination sur un sous‑ensemble labellisé.
- Économie : coût par action réussie (pas par token), taux de hit du cache et requêtes vectorielles par tâche.
- Fiabilité : taux de transfert à l’humain, taux d’auto‑retry, et incidents pour 10 k tâches.
- Sécurité des changements : % de montées de version de modèle annulées, temps moyen de rollback.
Ce que nous voyons sur le terrain
Sur des déploiements récents, quelques motifs se confirment :
- Le pré‑traitement en edge + des « cerveaux » régionaux est un sweet spot pour l’UX grand public. Attendez‑vous à 20 à 35 % d’amélioration de latence et 10 à 25 % de réduction de coûts LLM quand vous délestez classification/reranking vers de petits modèles en edge.
- Les modèles ouverts auto‑hébergés couvrent 60 à 80 % des tâches d’agents back‑office quand on les combine avec des prompts soignés, des adaptateurs LoRA et une politique d’outils stricte — libérant les modèles premium pour les 20 à 40 % les plus difficiles.
- Les sandboxes d’agents s’amortissent d’elles‑mêmes. Les équipes qui ont déplacé l’automatisation desktop dans des microVM ont réduit le risque d’incident et diminué le temps moyen d’investigation de plus de 50 % grâce à la relecture déterministe et à des journaux de session complets.
Rien de tout cela n’est théorique. C’est la couche opérationnelle dont vous aurez besoin si vous voulez passer d’une démo à une capacité durable.
Planifier la rareté et le changement
Un récit crédible sur « le début de la rareté en IA » implique des contraintes de capacité et des prix fluctuants. N’ancrez pas votre produit à un seul modèle ou fournisseur. Construisez un petit routeur ennuyeux avec des interfaces d’adaptateurs pour prompts, outils et garde‑fous. Gardez au moins une voie modèle ouvert au chaud (même si ce n’est que pour 10 % du trafic). Votre futur vous vous remerciera quand les rate limits ou les prix changeront en milieu de trimestre.
La conclusion
Choisissez la couche d’inférence qui correspond à votre profil de latence et de données, puis concevez les garde‑fous et l’observabilité comme si vous construisiez un système de paiement. Si vous faites cela, le modèle peut changer sous vos pieds — votre produit continuera de fonctionner.
Points clés
- Décidez par topologie et contrôle, pas par FOMO de modèles : edge pour la vitesse, VPC pour les données sensibles, hybride pour la plupart des vrais produits.
- Définissez dès maintenant votre niveau d’agent le plus élevé (0–4) ; il détermine l’isolation, l’IAM et le budget infra.
- L’edge Cloudflare est excellent pour l’UX chat+RAG ; Bedrock/auto‑hébergé gagnent pour les agents internes à forte contrainte de conformité et d’audit.
- Routez la cognition premium avec parcimonie ; poussez embeddings/rerankers et caches à l’edge pour réduire à la fois latence et coûts.
- Faites des modèles un flag de config. Gardez une échappatoire modèle ouvert au chaud pour gérer pannes et chocs de prix.
- Instrumentez les spans, lancez des évaluations nocturnes et entraînez‑vous aux rollbacks. C’est ainsi que vous évitez les régressions silencieuses de qualité.
- Pour les agents desktop/console, isolez dans des microVM éphémères avec enregistrement et budgets stricts. Moins que cela, c’est une brèche en attente.