O agente de IA que você demonstrou em um notebook não é o agente que você vai colocar em produção. O que determina se ele será rápido, em conformidade, econômico e observável não é o nome do modelo no seu slide — é a camada de inferência que você escolhe e como a projeta ao redor.
Nas últimas semanas, a Cloudflare apresentou uma camada de inferência “projetada para agentes”, levando computação para a borda. A OpenAI expandiu capacidades de controle de desktop, fazendo com que agentes que usam seu computador em segundo plano pareçam desconfortavelmente reais. A Mozilla apresentou um cliente focado em infraestrutura auto-hospedada. Enquanto isso, modelos abertos como Qwen3.6-35B estão ganhando capacidade de atuar como agentes. Tradução: a decisão de plataforma agora é a decisão de produto.
Se você é CTO, precisa escolher um caminho. Aqui vai um framework pragmático para fazer isso.
A escolha real não é “qual modelo?”; é “onde e como vamos executá-lo?”
Benchmarks e leaderboards são barulhentos. O que importa em produção é orçamento de latência, controle de dados, estabilidade de custo e operabilidade. Um agente que parece responsivo com p50 de 250 ms e p95 de 800 ms, com trilha de auditoria limpa, vence um agente ligeiramente “mais inteligente” que leva 2,5 s e espalha segredos nos logs.
Defina o nível de capacidade do seu agente (e o risco implícito)
- Nível 0: Chat e RAG. Perguntas e respostas sem estado. Uso mínimo de ferramentas. Baixo raio de impacto.
- Nível 1: Chamadas de função e orquestração de APIs. Escrita em sistemas internos sob IAM rigoroso.
- Nível 2: Navegação, I/O de arquivos e execução de código em sandbox. Raio de impacto médio.
- Nível 3: Controle de desktop ou console na nuvem (ex.: shell, automação de GUI). Alto raio de impacto, requer isolamento e gravação.
- Nível 4: Loops autônomos com tarefas em segundo plano e agendamento. Maior raio de impacto. Trate como uma conta de serviço privilegiada, com freios.
A escolha da camada de inferência deve acompanhar o nível mais alto que você pretende suportar nos próximos dois trimestres — não a demo que você rodou semana passada.
Um framework de decisão em sete perguntas
1) Qual é seu orçamento de latência e onde estão seus usuários?
- Inferência na borda (por exemplo, executando em uma rede global) pode reduzir 50–150 ms ao eliminar saltos de longa distância e cold starts para experiências de chat+RAG.
- Inferência regional (AWS, GCP, Azure) adiciona 30–120 ms por chamada, dependendo de peering e configuração de VPC. Muitas vezes é preferível para fluxos de backoffice.
- No dispositivo pode chegar a 30–80 ms para modelos pequenos, mas sacrifica capacidade e consistência; ótimo para tarefas com forte requisito de privacidade ou ocasionais.
Regra prática: se seu recurso de produto precisa parecer instantâneo (p95 abaixo de 1 s) e seus usuários são globais, favoreça a borda ou uma arquitetura dividida com roteador na borda, embeddings/rerankers locais e um “cérebro” regional.
2) Quais dados você toca e onde eles precisam residir?
- PHI, PCI ou políticas rígidas de PII empurram você para inferência hospedada na VPC ou provedores com residência de dados exigível e sem treinamento nas entradas.
- Minimização de dados e tokenização no gateway reduzem risco e lock-in de fornecedor. Redija/mascare antes da inferência, não depois.
- Para residência na UE/América Latina, planeje deploys duplos. Saltos transfronteiriços vão matar tanto a latência quanto a narrativa de compliance.
3) Quais ferramentas o agente vai usar e como você as coloca em sandbox?
- Chamadas de função em serviços internos exigem requisições assinadas, allowlists por ferramenta e tetos de orçamento por rodada.
- Controle de desktop ou console exige VMs/microVMs efêmeras, gravação de sessão e credenciais por tarefa com RBAC de escopo restrito.
- Navegação web precisa de renderizadores seguros e sanitização de conteúdo; não permita que um agente execute JavaScript arbitrário na sua rede de produção.
4) Qual SLA e risco de fornecedor você tolera?
- Endpoints públicos de provedores fechados entregam modelos de ponta, mas podem impor throttling ou mudar termos. Tenha um modelo fallback e uma camada de roteamento.
- Redes de borda podem ser resilientes, mas adicionam dependência na disponibilidade dos POPs e nos recursos do fornecedor. Valide o backlog de modelos suportados e a cadência de upgrades.
- Auto-hospedar dá controle, mas coloca o plantão de uptime no seu time. Reserve horas de SRE. Não existe almoço grátis.
5) Você consegue fazer a unit economics convergir?
Trabalhe de trás para frente a partir de uma tarefa: média de 300 tokens de entrada, 800 tokens de saída, 2 chamadas de função. Multiplique pelo seu volume mensal de tarefas. Depois construa dois cenários:
- Modelo fechado premium para cognição + reranker/embedding aberto e barato na borda.
- Stack totalmente aberto, ajustado/fine-tuned com LoRA para o seu domínio.
Vemos regularmente variações de custo de 20–40% dependendo do quanto você descarrega em rerankers e de quão agressivamente faz batch ou cache de embeddings. Considere também o egresso do DB vetorial; manter rerank e busca vetorial co-localizados com a inferência evita contas de rede desnecessárias.
6) Como você vai observar, avaliar e reverter?
- Cada passo do agente deve emitir spans com ferramenta, tokens, latência e custo. Faça amostragem de prompts/completions brutos com redação.
- Rode evals sintéticos noturnos em um corpus fixo. Acompanhe taxa de sucesso e deltas de alucinação por versão do modelo.
- Transforme modelos em um toggle de configuração. Entregue com kill switch e treine rollbacks como você treina resposta a incidentes.
7) Qual é sua rota de escape?
- Mantenha prompts, esquemas de ferramentas e guardrails agnósticos ao provedor. Use uma camada de adaptação para que trocas de modelo não atinjam o código de produto.
- Mantenha pelo menos um caminho com modelo open source (vLLM/ollama) para continuidade durante indisponibilidades do fornecedor ou mudanças de preço.
Suas opções de plataforma, sem hype
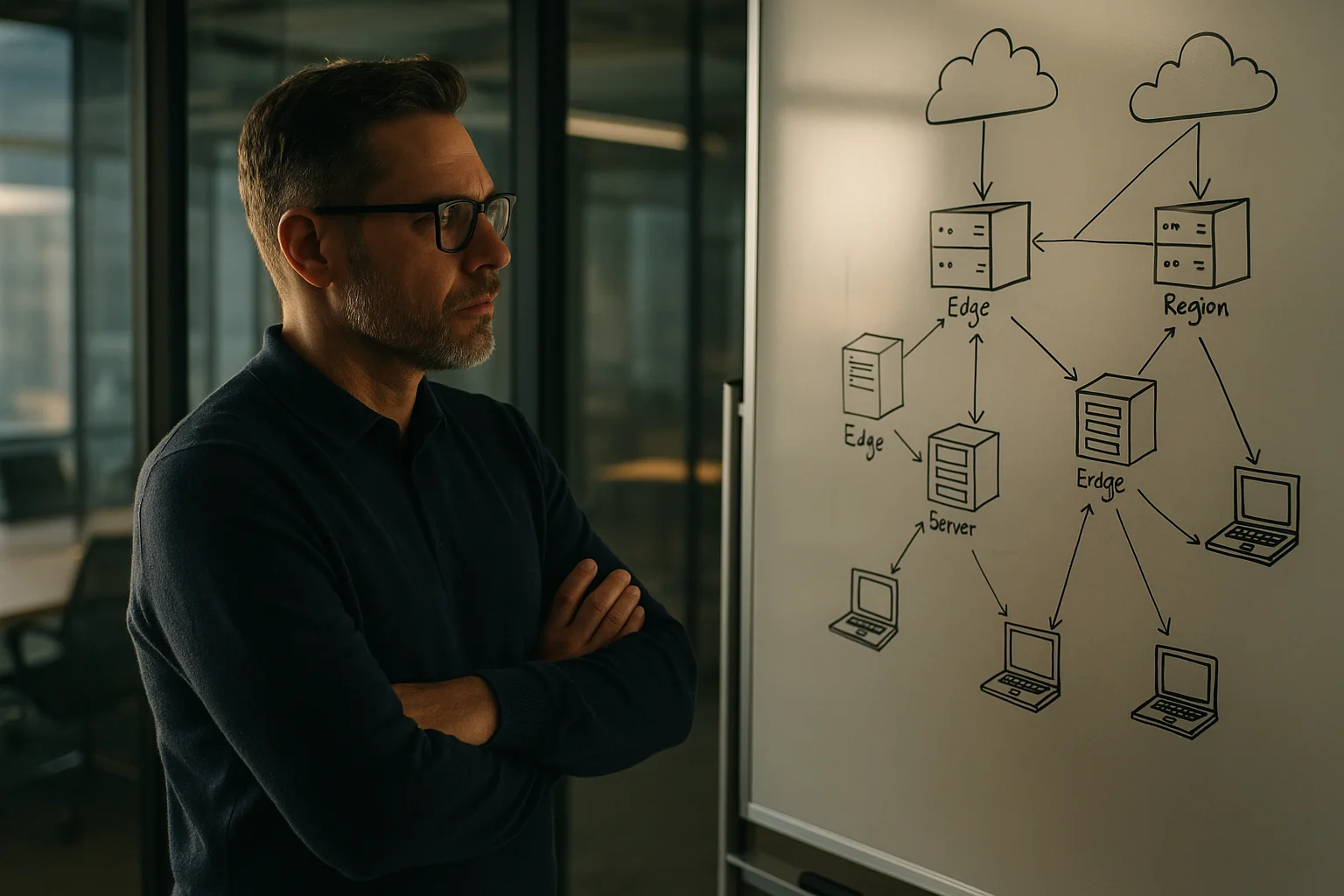
Cloudflare Workers AI (edge) + Vectorize + KV/Queues
A Cloudflare está explicitamente posicionando sua plataforma de IA como uma camada de inferência para agentes, com POPs globais e integração estreita entre storage e rede. Na prática: mínimos cold starts, caudas de latência rápidas e movimentação de dados intra-plataforma barata.
- Forças: 300+ POPs, latência próxima do usuário; composição fácil com KV/Queues/Durable Objects; bom encaixe para chat+RAG e uso leve de ferramentas.
- Restrições: profundidade do catálogo de modelos varia; jobs de longa duração ou muito pesados em GPU podem ser incômodos; opções de fine-tuning são limitadas em comparação aos hyperscalers. Você aceita o roadmap de features do fornecedor como fator limitante.
- Bom encaixe: recursos de produto onde p95 abaixo de 1 s importa e a sensibilidade de dados é gerenciável com redação/tokenização.
Referência: veja a visão geral da plataforma de IA da Cloudflare para suporte atual a modelos e padrões arquiteturais (blog.cloudflare.com/ai).
AWS Bedrock + Lambda/ECS + VPC (regional)
O Bedrock oferece um menu de modelos fechados e abertos de alta qualidade dentro do limite da sua VPC, com suporte a IAM e PrivateLink. É “chato” no melhor sentido.
- Forças: IAM nível enterprise, CloudWatch, KMS; história de compliance; co-localização com suas fontes de dados; evolução constante (agents, guardrails).
- Restrições: latência regional; opacidade de custo ao misturar serviços gerenciados; ocasionais restrições de capacidade de modelo; você ainda precisa desenhar seu próprio roteamento e evals.
- Bom encaixe: agentes de backoffice, workloads com PII/PHI, automação interna onde auditabilidade vence latência absoluta.
Endpoints da OpenAI/Anthropic (cognição gerenciada)
Modelos de raciocínio de ponta, forte function calling, planejamento de uso de ferramentas e agora capacidades de sistema cada vez mais assertivas como controle de desktop em segundo plano.
- Forças: raciocínio e coding de melhor classe; melhorias frequentes de modelos; fácil de prototipar; boa semântica de uso de ferramentas.
- Restrições: termos do fornecedor e rate limits; controle de dados depende de configurações e acordos enterprise; salto pela internet pública e egresso; sandbox é responsabilidade sua.
- Bom encaixe: quando a qualidade de raciocínio domina e você pode mitigar risco de dados via redação, ou para chamadas de “cérebro” atrás de uma borda/roteador com pré/pós-processamento em modelos abertos.
Referência: blogs dos provedores anunciam mudanças rápidas de capacidade; planeje o controle de mudanças (openai.com/blog, anthropic.com/news).
Modelos abertos auto-hospedados com vLLM/Ollama em Kubernetes (VPC)
Se controle de dados e previsibilidade de custo pesam mais que QI bruto, auto-hospede. O vLLM oferece serving de alta vazão; modelos abertos modernos (Qwen, Llama, Mistral) estão se tornando muito capazes, especialmente com ajuste ao domínio e reranking.
- Forças: controle total de dados; custo previsível por hora de GPU; pode rodar modelos quantizados em GPUs/CPUs menores para caminhos não críticos; evita lock-in.
- Restrições: você faz SRE; ciclo de vida de modelo e disciplina de avaliação são por sua conta; para sustentar state of the art é preciso tuning contínuo.
- Bom encaixe: dados regulados, cenários offline/air-gapped ou RAG de alto volume sensível a custo, onde qualidade no p95 não é mandatória.
No dispositivo (mobile/desktop)
Com modelos pequenos e quantizados e NPUs móveis cada vez mais capazes, inferência no dispositivo é real para tarefas estreitas (sumarização, classificação, redação no cliente, verificação de idade).
- Forças: privacidade, capacidade offline, menor latência de rede, potenciais ganhos de compliance quando a inferência nunca sai do dispositivo.
- Restrições: tamanho e contexto de modelo limitados; complexidade de distribuição e upgrade; aceleração de hardware fragmentada.
- Bom encaixe: features privacy-first, pré/pós-processamento, filtragem antes da cognição no servidor.
Arquiteturas de referência que chegam à produção
1) Recurso consumer: chat + RAG de baixa latência
- Roteador na borda na Cloudflare (ou similar) para terminação de requisições, redação, rate limiting e feature flags.
- Embeddings e rerankers na borda para seleção de candidatos a partir de um vetor store co-localizado. Faça cache agressivamente.
- Chamadas de “cérebro” para um modelo premium regional (OpenAI/Anthropic ou Bedrock) apenas quando necessário. Contextos curtos, ferramentas com guardrails.
- Observabilidade: logging em nível de span com contagem de tokens, p50/p95 por estágio e transcrições amostradas com PII mascarada.
Vimos isso reduzir a latência mediana em 25–35% versus designs “apenas regionais”, com redução de 15–25% no gasto com LLM graças ao pré-filtro mais inteligente.
2) Agente interno de backoffice com dados sensíveis
- Rode a inferência na sua VPC (Bedrock ou vLLM) atrás de um gateway OIDC. Todas as ferramentas exigem JWTs assinados e papéis IAM por escopo.
- Centralize segredos no seu cofre padrão; nunca em prompts. Registre todas as invocações de ferramentas em um repositório append-only.
- Use um motor de políticas para aprovar/negar ações acima de um limiar de risco (ex.: pagamento > US$ 1000 requer confirmação humana).
- Evals noturnos em um conjunto de dados de referência; gates de regressão bloqueiam novas versões de modelo que piorem além das margens acordadas.
Espere latências um pouco maiores (p95 de 900–1400 ms), mas forte auditabilidade e governança de dados que passam por revisões externas.
3) Automação de desktop/console (alto raio de impacto)
- Nunca deixe o agente tocar no desktop real de um usuário. Suba microVMs ou containers efêmeros com identidade descartável e credenciais por execução.
- Use um “cérebro” em duas camadas: modelo fechado para planejamento; modelo aberto auto-hospedado para passos iterativos de baixo risco, para controlar custo e evitar rate limits.
- Grave a sessão (vídeo + logs), limite tempo de execução e orçamentos de tokens, e exija aprovação humana para ações destrutivas.
- Passe todos os downloads por um renderizador seguro e varredura AV. Egresso de rede travado por allowlists.
Sim, é mais pesado. Mas essa é a diferença entre um demo controlado e um sistema de produção que você consegue defender em uma revisão de incidente.
Controles de segurança que importam mais do que a escolha do modelo
- Redação na borda: remoção de hash/e-mail/SSN antes dos prompts. Mantenha os originais em um repositório selado, indexados por um token caso precise reidratar pós-inferência.
- Allowlists de ferramentas + orçamentos: N máx. de chamadas de ferramenta por rodada, gasto máximo por sessão e escopos por ferramenta. Negue por padrão.
- Timeboxing: timeouts rígidos e watchdogs nos loops do agente. Nada de jobs eternos em segundo plano sem schedulers que você controla.
- Linagem de dados: etiquete cada artefato com versão do modelo, hash do prompt e cadeia de ferramentas. Torne possível responder “o que produziu isso?”
- Testes de jailbreak no CI: prompts de red team versionados no seu repositório. Rode-os contra cada upgrade de modelo antes do rollout.
Medição de sucesso: KPIs que mantêm você honesto
- Latência: p50/p95 por estágio (embed, rerank, LLM, ferramentas), não apenas ponta a ponta.
- Qualidade: taxa de sucesso de tarefas nas evals noturnas; taxa de factualidade/alucinação em um subconjunto rotulado.
- Economia: custo por ação bem-sucedida (não por token), taxas de acerto de cache e consultas vetoriais por tarefa.
- Confiabilidade: taxa de handoff humano, taxa de auto-retry e incidentes por 10 mil tarefas.
- Segurança de mudanças: % de upgrades de modelo revertidos, tempo médio para rollback.
O que estamos vendo em campo
Em implantações recentes, alguns padrões se mantêm:
- Pré-processamento na borda + “cérebros” regionais é o sweet spot para UX consumer. Espere melhorias de latência de 20–35% e reduções de custo de LLM de 10–25% quando você descarrega classificação/reranking para modelos pequenos na borda.
- Modelos abertos auto-hospedados são viáveis para 60–80% das tarefas de agentes de backoffice quando combinados com prompts curados, adaptadores LoRA e uma política de ferramentas rígida — liberando modelos premium para os 20–40% mais difíceis.
- Sandboxes de agentes se pagam. Times que moveram automação de desktop para microVMs reduziram drasticamente o risco de incidentes e cortaram o tempo médio de investigação em mais de 50% graças a replay determinístico e logs completos de sessão.
Nada disso é teórico. É a camada operacional de que você vai precisar se quiser sair do demo para uma capacidade durável.
Planeje para escassez e mudança
Uma narrativa crível sobre “o início da escassez em IA” implica que restrições de capacidade e preços vão oscilar. Não ancore seu produto a um único modelo ou provedor. Construa um roteador pequeno e “chato”, com interfaces de adaptação para prompts, ferramentas e guardrails. Mantenha pelo menos um caminho com modelo aberto aquecido (mesmo que seja só 10% do tráfego). Seu eu do futuro vai agradecer quando limites de taxa ou preços mudarem no meio do trimestre.
A moral da história
Escolha a camada de inferência que combina com seu perfil de latência e dados, depois desenhe guardrails e observabilidade como se estivesse construindo um sistema de pagamentos. Se você fizer isso, o modelo pode mudar por baixo — e seu produto continuará funcionando.
Principais conclusões
- Decida por topologia e controle, não por FOMO de modelo: borda para velocidade, VPC para dados sensíveis, híbrido para a maioria dos produtos reais.
- Defina agora o nível mais alto do seu agente (0–4); ele determina sandboxing, IAM e orçamento de infra.
- A borda da Cloudflare é ótima para UX de chat+RAG; Bedrock/auto-hospedado vence para agentes internos com forte demanda de compliance e auditoria.
- Encaminhe cognição premium com parcimônia; leve embeddings/rerankers e caches para a borda para cortar latência e custo.
- Trate modelos como uma flag de configuração. Mantenha aquecida uma rota de escape com modelo aberto para lidar com indisponibilidades e choques de preço.
- Instrua spans, rode evals noturnos e pratique rollbacks. É assim que você evita que a qualidade regrida silenciosamente.
- Para agentes de desktop/console, isole em microVMs efêmeras com gravação e orçamentos estritos. Qualquer coisa menos é uma brecha em espera.
Autor: Diogo Hudson Dias